 Português
Português  English
English
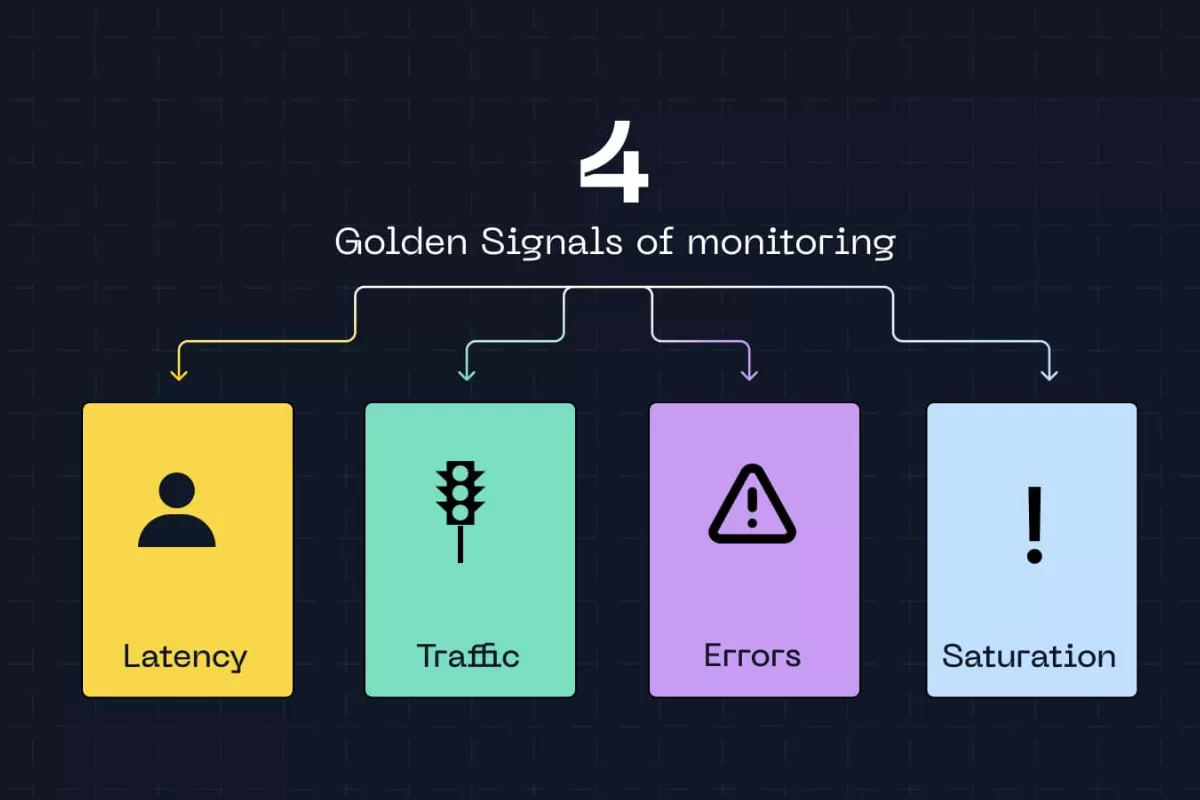
Os Golden Signals foram idealizados pela equipe de SRE (Site Reliability Engineering) do Google, e revolucionaram a forma como profissionais de tecnologia enxergam monitoramento.
Eles são quatro métricas fundamentais: latência, tráfego, erros e saturação. Juntas, elas oferecem uma visão completa da saúde de qualquer sistema sem a necessidade de acompanhar centenas de indicadores ao mesmo tempo.
Segundo pesquisa da Dimensional Research (2023), 94% das organizações que sofreram downtime crítico apontaram que a identificação tardia do problema foi o principal motivo para o tempo prolongado de indisponibilidade. Pensando em evitar isso, escrevemos esse artigo. Vamos lá?

O que são Golden Signals?
Golden Signals são um conjunto de quatro métricas essenciais para avaliar se um sistema está funcionando adequadamente ou caminhando para uma falha. O termo “golden” (ouro, em inglês) não é exagero, essas métricas são valiosas porque, com apenas quatro indicadores, você consegue detectar a maioria dos problemas que afetam aplicações e infraestruturas modernas.
- Latência: mede quanto tempo o sistema demora para responder a uma requisição. Desde o momento em que um usuário clica em um botão até receber a resposta na tela, esse intervalo é a latência. Ela pode ser medida em milissegundos, segundos ou até minutos, dependendo do tipo de operação.
- Tráfego: indica o volume de requisições que o sistema está processando. Pode ser medido em requisições por segundo, transações por minuto ou até GB de dados transferidos.
- Erros: contabilizam quantas requisições falharam. Isso inclui páginas que não carregaram, transações que não foram concluídas, timeouts e qualquer resposta inesperada do sistema. Normalmente expressa-se essa métrica como taxa percentual de erro.
- Saturação mostra o quanto dos recursos disponíveis está sendo utilizado. CPU a 90%, memória quase cheia, disco com pouco espaço livre — tudo isso indica saturação. É a métrica que revela se o sistema está próximo do limite antes de começar a falhar.
Como funciona cada Golden Signal na prática
Latência
Latência é provavelmente a métrica mais perceptível para usuários finais. Quando uma página demora a carregar ou um aplicativo trava, estamos sentindo latência alta na pele. Para sistemas de TI, latência engloba tempo de resposta de APIs, consultas a bancos de dados, processamento de requisições e comunicação entre serviços.
O monitoramento eficaz de latência vai além de calcular uma média simples. Equipes maduras trabalham com percentis, especialmente o percentil 95 (p95) e o percentil 99 (p99). Por quê? Porque médias escondem problemas. Se 95% das requisições respondem em 200ms e 5% demoram 10 segundos, a média pode parecer aceitável, enquanto milhares de usuários enfrentam lentidão insuportável.
Estudo da Akamai (2017) revelou que um atraso de apenas 100 milissegundos no tempo de carregamento pode reduzir as taxas de conversão em 7%.
Monitorar latência também ajuda a criar SLOs (Service Level Objectives) realistas. Em vez de prometer “sistema rápido”, você pode comprometer-se com “95% das requisições respondidas em menos de 300ms”.
Tráfego
Tráfego mede a demanda sobre seu sistema. Para uma API, isso significa requisições por segundo. Para um site, pode ser pageviews por minuto. Para um serviço de processamento de dados, talvez seja o número de jobs executados por hora. Independente da unidade, tráfego revela se seu sistema está ocupado, ocioso ou enfrentando picos anormais.
Uma queda brusca de tráfego pode ser tão problemática quanto um pico. Imagine que seu sistema normalmente processa 5.000 requisições por minuto e, de repente, esse número cai para 500. Isso pode indicar que algo está impedindo usuários de acessarem o serviço, talvez uma falha no load balancer, problema de DNS ou até um ataque DDoS que deixou parte da infraestrutura inacessível.

Segundo relatório da Gartner, o custo médio de downtime para empresas é de US$ 5.600 por minuto. Para organizações que dependem de sistemas digitais, cada segundo de indisponibilidade custa caro. Tráfego também alimenta decisões de capacity planning. Se você percebe crescimento consistente de 20% ao mês, sabe que precisa escalar recursos antes que saturação vire problema.
Erros
Taxa de erros é talvez a métrica mais direta para medir a saúde de um sistema. Erros podem assumir várias formas: HTTP 500 (erro interno do servidor), 404 (recurso não encontrado), timeouts, exceções não tratadas no código ou falhas de integração com serviços externos.
Nem todo erro tem o mesmo peso. Um usuário que digitou uma URL errada e recebeu 404 é diferente de mil clientes que tentam finalizar compras e recebem erro 500 porque o sistema de pagamento caiu. Por isso, monitoramento eficaz de erros separa falhas por tipo e severidade.
Uma abordagem comum é definir budgets de erro, ou seja, quanto erro é aceitável. Nenhum sistema complexo terá zero erros o tempo todo, então estabelecer que “taxa de erro deve ficar abaixo de 0,1%” é mais realista do que buscar perfeição absoluta. Quando esse threshold é ultrapassado, disparam-se alertas e investigações.
A correlação entre erros e outras métricas também traz insights valiosos. Se taxa de erro aumenta junto com latência e saturação de CPU, provavelmente há um problema de performance que leva a timeouts. Se erros sobem enquanto latência permanece normal, talvez seja um bug recém-introduzido no código.
Saturação
Saturação indica o quanto você está usando dos recursos disponíveis. CPU, memória, espaço em disco, largura de banda de rede, conexões de banco de dados, tudo tem limite. Quando esses recursos se aproximam de 100% de utilização, problemas aparecem.
A particularidade da saturação é que ela funciona como indicador preditivo. Enquanto latência, tráfego e erros mostram problemas já acontecendo, saturação avisa que algo ruim está prestes a ocorrer. É como ver o tanque de combustível chegando no vermelho antes do carro parar.
Thresholds de saturação variam por recurso. CPU a 70-80% já merece atenção, pois picos momentâneos podem levá-la a 100% rapidamente. Memória acima de 85% é preocupante porque pode forçar o sistema operacional a usar swap, degradando performance drasticamente. Disco com menos de 10% de espaço livre pode impedir gravação de logs ou dados críticos.
Monitorar saturação também revela ineficiências. Se CPU permanece consistentemente alta com tráfego moderado, talvez haja código mal otimizado consumindo processamento desnecessário. Memória crescendo constantemente pode indicar memory leak. Conexões de banco de dados sempre no limite sugerem que pooling está mal configurado. Segundo pesquisa da New Relic (2021), 75% das organizações experimentam problemas de performance relacionados a infraestrutura ao menos uma vez por mês.
Implementando Golden Signals: do conceito à prática
O processo de implementar Golden Signals começa com instrumentação adequada do código e infraestrutura. Aplicações precisam expor métricas que podem ser coletadas por ferramentas de monitoramento. Na prática, isso significa adicionar bibliotecas de instrumentação (como Prometheus client libraries, OpenTelemetry ou SDK de ferramentas APM) ao código.
Para latência, você instrumenta pontos de entrada e saída das requisições, medindo tempo decorrido. Frameworks web modernos geralmente já incluem middlewares que fazem isso automaticamente. Para tráfego, contam-se requisições recebidas, normalmente através de contadores que incrementam a cada chamada. Erros são capturados através de try-catch blocks e logging estruturado que classifica exceções por tipo e severidade.

Saturação requer acesso a métricas do sistema operacional e runtime. Ferramentas como node_exporter (para Linux), cAdvisor (para containers) ou SDKs específicos de linguagem expõem uso de CPU, memória, disco e rede. Em ambientes cloud, provedores como AWS, GCP e Azure oferecem essas métricas nativamente.
Depois de coletar dados, você precisa armazená-los em sistema de time-series database (TSDB) como Prometheus, InfluxDB ou soluções gerenciadas como Datadog e New Relic. Esses bancos são otimizados para grandes volumes de dados temporais e consultas rápidas sobre intervalos de tempo.
Visualização acontece através de dashboards. Grafana é escolha popular para criar painéis customizados que mostram Golden Signals em tempo real. A chave é evitar dashboards poluídos, crie visualizações focadas que destacam os quatro sinais principais.
Alerting é onde métricas se tornam acionáveis. Configure alertas baseados em thresholds: “avisar quando latência p95 > 1s por mais de 5 minutos” ou “disparar página quando taxa de erro > 2%”. Cuidado com alert fatigue, pois alertas demais dessensibilizam equipe.
Ferramentas sozinhas não bastam. Expertise técnica faz diferença entre ter métricas e realmente aproveitar seu valor. Equipes precisam entender como interpretar dados, correlacionar sinais e agir rapidamente quando problemas aparecem.
NextAge e monitoramento de excelência
Golden Signals estabelecem fundação para monitoramento, porém um bom processo de desenvolvimento exige profissionais experientes, que dominam todas as boas práticas.
Na NextAge, nossa abordagem em desenvolvimento e sustentação de sistemas sempre incorpora observabilidade como requisito fundamental.
Nosso Quality Center combina especialistas em QA com automação impulsionada por Inteligência Artificial para garantir que problemas sejam detectados e resolvidos antes de chegarem à produção. Squads dedicados trabalham em validação técnica e funcional, usando Golden Signals como parte do processo de teste. Latência é medida em testes de carga, erros são rastreados em testes de integração, saturação é monitorada durante stress testing.
Já em nosso Outsourcing 2.0, alocamos squads ágeis completos que trazem cultura de dados embutida no DNA. Profissionais validados técnica e comportamentalmente entendem que entregar funcionalidade é só metade do trabalho, pois a outra metade é garantir que essa funcionalidade permaneça confiável ao longo do tempo.
Por fim, os serviços de Sustentação de Sistemas 2.0 vão além do suporte corretivo tradicional. Atuamos proativamente usando Golden Signals para identificar problemas antes que vire indisponibilidade. Monitoramos latência crescente que indica necessidade de otimização, rastreamos erros intermitentes que podem explodir em falhas maiores, observamos saturação gradual que sinaliza hora de escalar recursos.
Quer conversar sobre como podemos construir ou sustentar sistemas que geram valor ao seu negócio? Entre em contato e descubra como transformar monitoramento de reativo para proativo.









