English
English  Português
Português
Imagine this: You’re driving down a winding road, and the only way to stay on the right path is by relying on an updated GPS. In the world of software development, DORA Metrics act like that GPS, guiding IT teams toward operational excellence. These metrics not only help you understand where your company stands but also illuminate the road to achieving better outcomes.
But what exactly are DORA Metrics? Where did they come from? And, more importantly, how can they transform your team’s performance? Let’s dive in.
What Are DORA Metrics and How Did They Come About?
DORA Metrics are a set of indicators designed to measure the performance of DevOps teams. The concept was introduced by the DevOps Research and Assessment (DORA) team after years of research involving thousands of professionals. Their goal was simple: to identify the practices and metrics that truly drive efficiency in software development and delivery.
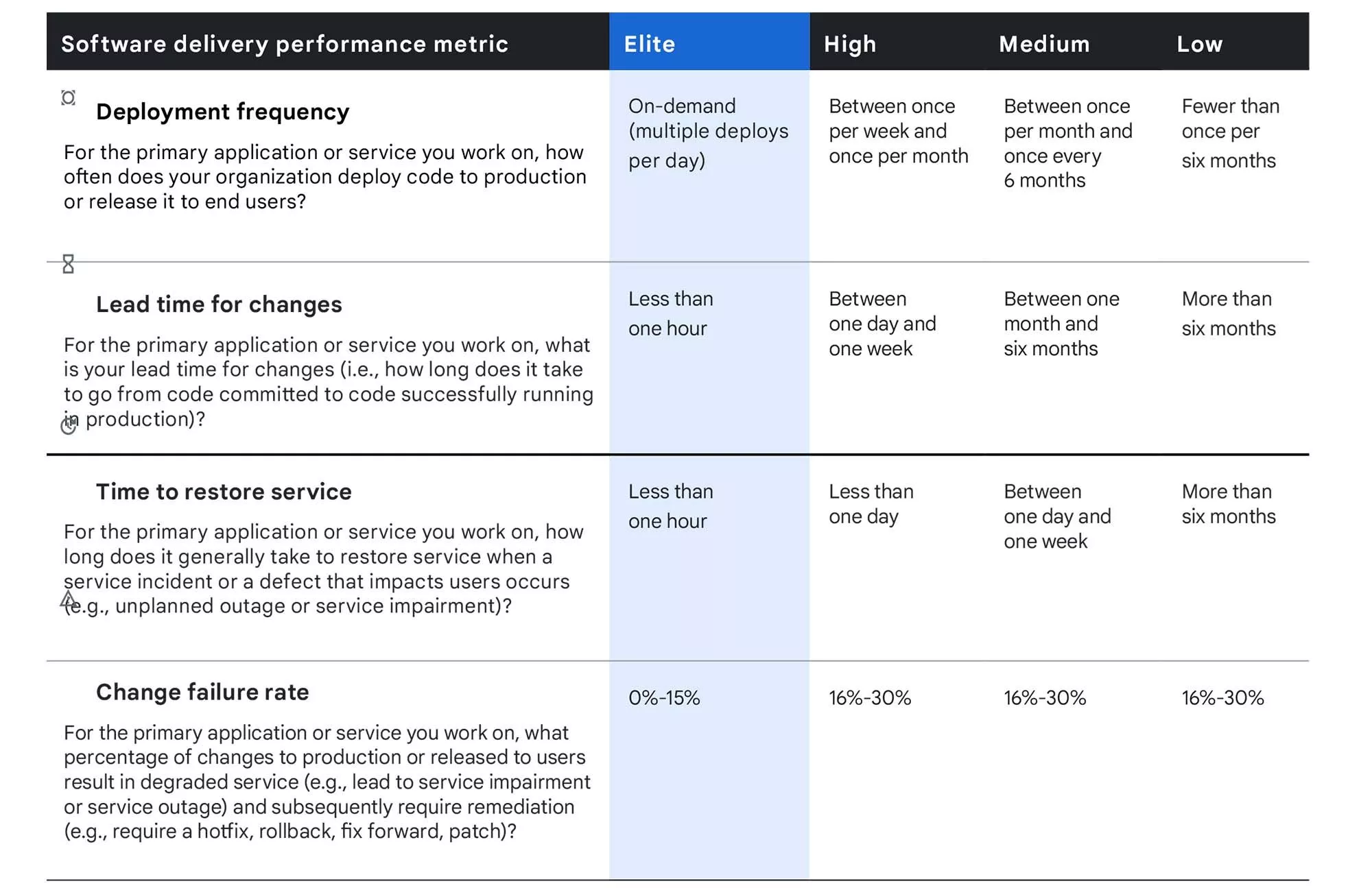
The result was the identification of four key metrics: Deployment Frequency, Lead Time for Changes, Time to Restore Service, and Change Failure Rate. Together, these metrics assess both the speed and stability of IT operations, offering a comprehensive view of a company’s maturity level.
Think of these metrics as a health check for your IT team. By analyzing them, you can pinpoint strengths and bottlenecks, allowing you to prioritize improvements that make the biggest impact.
The 4 Levels of DORA Metrics Maturity
DORA Metrics classify companies into four levels of performance:
- Elite: High-performing teams that excel in both speed and stability.
- High: Teams with solid practices but room for improvement.
- Medium: Teams with functional processes but lacking in peak efficiency.
- Low: Underperforming operations with low efficiency and many bottlenecks.
Now, let’s break down each of the four DORA Metrics and how they work in practice.
1. Deployment Frequency

2. Lead Time for Changes
The Lead Time for Changes metric measures the time between when an idea is coded (commit) and when it reaches the end user. In other words, it reflects the efficiency of your development pipeline: the more agile and well-structured your pipeline is, the shorter this time will be.
The performance levels for this metric are:
- Elite: Less than 1 day for a change to be deployed.
- High: Between 1 day and 1 week.
- Medium: Between 1 week and 1 month.
- Low: More than 1 month.
If your team takes weeks or even months to transform a commit into something functional for the user, that’s a red flag. This often signals excessive dependencies, manual processes, or bottlenecks in automation. These delays don’t just slow down the delivery of value—they also increase the risk that changes will become outdated or irrelevant before they even reach the market.
Elite-level companies understand that speed and quality go hand in hand. By reducing Lead Time, they focus on smaller, more frequent deliveries, which allow for quick and continuous adjustments. This approach not only improves work predictability but also boosts customer satisfaction by ensuring the product or service is constantly evolving in meaningful ways.
To reach this level, investing in practices like continuous integration, test automation, and optimized pipelines is essential. The shorter your Lead Time for Changes, the faster you’ll be able to respond to market demands—and the greater your competitive edge will be.
3. Time to Restore Services
Failures happen. Even with the best practices in place, there will inevitably come a time when something goes wrong in production. That’s where the Time to Restore Services metric comes in. It measures how long your team takes to fix a problem and restore normal system functionality.
The performance levels for this metric are as follows:
- Elite: Resolves issues in less than 1 hour.
- High: Resolves issues between 1 hour and 1 day.
- Medium: Resolves issues between 1 day and 1 week.
- Low: Takes more than 1 week to restore services.
Response time is critical. The longer a service remains down or impaired, the greater the impact on users and the business. Whether it’s an e-commerce outage, a banking system error, or a failure in a critical application, the consequences range from revenue loss to significant damage to your company’s reputation.

Elite teams stand out by acting swiftly to minimize these impacts. They achieve this through clear processes, advanced monitoring tools, and well-trained teams prepared to handle incidents. Their speed doesn’t come from improvisation but from strategic preparation—such as running failure simulations, automating diagnostics, and fostering a collaborative culture between development and operations teams.
Investing in Time to Restore Services isn’t just about avoiding extended downtimes. It’s about ensuring that when problems do arise, your company is ready to address them efficiently and with minimal disruption. After all, customer trust is built not only on stability but also on your ability to recover quickly when the unexpected happens.
4. Change Failure Rate
The Change Failure Rate metric measures the percentage of deployments that result in issues in production. Simply put, it tracks how often planned changes don’t go as expected and need to be fixed. Here, quality is the key factor—after all, there’s no point in deploying changes quickly and frequently if many of them fail.
The performance levels for this metric are:
- Elite: Only 0% to 15% of deployments cause problems.
- High: Between 16% and 30%.
- Medium: Between 31% and 45%.
- Low: More than 45%.
Keeping the Change Failure Rate low is essential for maintaining trust in your product and your team. To achieve this, Elite-level organizations adopt practices like automation, rigorous testing, and continuous integration. These teams understand that quality is non-negotiable—each deployment undergoes thorough validation to minimize risks before reaching production.
On the other hand, companies in the Medium or Low categories often face challenges like inadequate testing, manual processes, and limited visibility into the impact of changes. This leads to problematic deployments that not only create extra work for the team but also negatively affect the end-user experience.
Another crucial factor is organizational culture. Teams with high failure rates often fall into the trap of blaming individuals instead of addressing process issues. High-performing teams, however, take a collaborative approach: they investigate the root cause of failures and implement improvements to prevent them from happening again.
Ultimately, the Change Failure Rate is more than just a technical performance metric; it’s a measure of organizational maturity. Investing in reducing this rate is an investment in customer trust, team performance, and the long-term sustainability of your business.
Where Does NextAge Fit In?
At NextAge, excellence isn’t just a goal—it’s our standard. With over 16 years of experience and a presence in 9 countries, we take pride in aligning our processes with the industry’s best practices, including the DORA Metrics. Our commitment to quality enables us to deliver multiple daily deployments with high stability and reduced response times to incidents.
Our methodology, validated both nationally and internationally, ensures that our clients receive fast, reliable results. Companies like Sicredi, Odebrecht, and Positivo trust us because they know our focus is on delivering continuous value without compromising quality.
Adopting the DORA Metrics isn’t just a checkbox for us—it’s a journey toward operational excellence. Ready to take your business to the next level? Talk to NextAge. We’re here to help your team navigate this transformation with confidence.